Như những người dùng Linux, chúng ta tương tác với các loại tệp khác nhau đều đặn. Một trong những loại tệp phổ biến nhất trên bất kỳ hệ thống máy tính nào là tệp văn bản thuần. Thường thì, điều này là một yêu cầu rất phổ biến để tìm kiếm văn bản cần thiết trong những tệp này.
Tuy nhiên, nhiệm vụ đơn giản này nhanh chóng trở nên khó chịu nếu tệp chứa các mục trùng lặp. Trong những trường hợp như vậy, chúng ta có thể sử dụng lệnh uniq để lọc văn bản trùng lặp một cách hiệu quả.
Trong Linux, chúng ta có thể sử dụng uniq command mà rất hữu ích khi chúng ta muốn liệt kê hoặc loại bỏ các dòng trùng lặp liền kề. Ngoài ra, chúng ta cũng có thể sử dụng lệnh uniq để đếm các mục trùng lặp. Chú ý rằng, lệnh uniq chỉ hoạt động khi các mục trùng lặp là liền kề.
Trong hướng dẫn đơn giản này, chúng ta sẽ thảo luận sâu về lệnh uniq với các ví dụ thực tế trong Linux.
Cú pháp lệnh uniq
Cú pháp của lệnh uniq rất dễ hiểu và tương tự như các lệnh Linux khác:
$ uniq [OPTIONS] [INPUT] [OUTPUT]
Chú ý rằng, tất cả các tùy chọn và tham số của lệnh uniq là không bắt buộc.
Tạo tệp văn bản mẫu
Để bắt đầu, trước tiên, hãy tạo một tệp văn bản đơn giản bằng trình biên tập vi và thêm nội dung trùng lặp sau đây nằm trong các dòng liền kề.
$ vi linux-distributions.txt
$ cat linux-distributions.txt
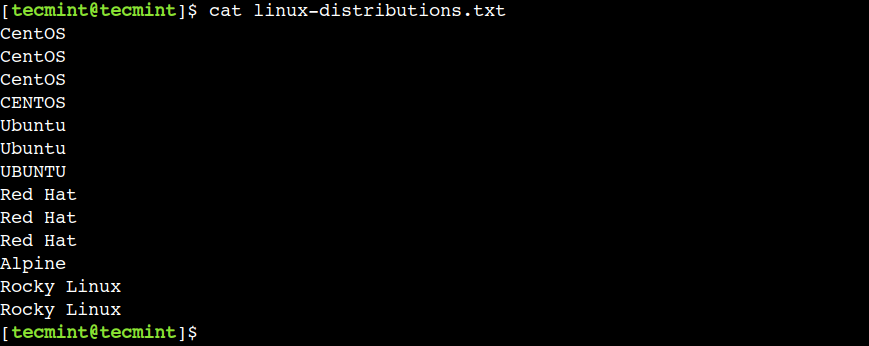
Bây giờ, hãy sử dụng tệp này để hiểu cách sử dụng lệnh uniq.
8 ví dụ về uniq command
1. Xóa dòng trùng lặp từ tệp văn bản
Một trong những ứng dụng thông thường của lệnh uniq là xóa những dòng trùng lặp liền kề từ tệp văn bản như được hiển thị.
$ uniq linux-distributions.txt
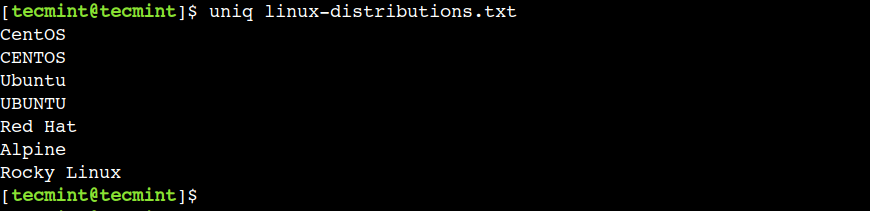
Trong đầu ra trên, chúng ta có thể thấy rằng lệnh uniq đã loại bỏ thành công các dòng bị trùng lặp.
2. Đếm các dòng trùng lặp trong một tệp văn bản
Trong ví dụ trước, chúng ta đã thấy cách xóa các dòng trùng lặp. Tuy nhiên, đôi khi chúng ta cũng muốn biết một dòng trùng lặp xuất hiện bao nhiêu lần.
Chúng ta có thể làm điều này bằng cách sử dụng tùy chọn -c như được hiển thị trong ví dụ dưới đây:
$ uniq -c linux-distributions.txt
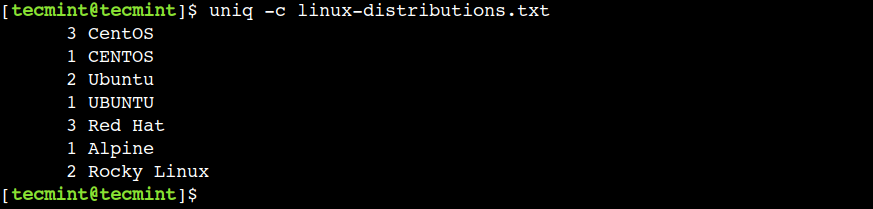
Trong đầu ra trên, cột đầu tiên biểu thị số lần dòng được lặp lại.
3. Xóa các dòng trùng lặp không phân biệt chữ hoa chữ thường
Mặc định, lệnh uniq hoạt động theo cách phân biệt chữ hoa chữ thường. Tuy nhiên, chúng ta có thể vô hiệu hóa hành vi mặc định này bằng cách sử dụng tùy chọn -i như được hiển thị.
$ uniq -i linux-distributions.txt

Trong ví dụ này, chúng ta có thể thấy rằng bây giờ, chuỗi Ubuntu và UBUNTU được coi là giống nhau. Bên cạnh đó, điều tương tự xảy ra với chuỗi CentOS và CENTOS.
4. In chỉ các dòng trùng lặp từ tệp
Đôi khi, chúng ta chỉ muốn in các dòng trùng lặp từ một tệp văn bản, trong trường hợp đó, bạn có thể sử dụng tùy chọn -d như được hiển thị.
$ uniq -d linux-distributions.txt

Trong đầu ra trên, chúng ta có thể thấy rằng lệnh uniq hiển thị mục trùng lặp từ mỗi nhóm.
5. In tất cả các dòng trùng lặp từ một tệp
Trong ví dụ trước, chúng ta đã thấy cách hiển thị một dòng trùng lặp từ mỗi nhóm. Tương tự, chúng ta cũng có thể hiển thị tất cả các dòng trùng lặp bằng cách sử dụng tùy chọn -D như sau:
$ uniq -D linux-distributions.txt
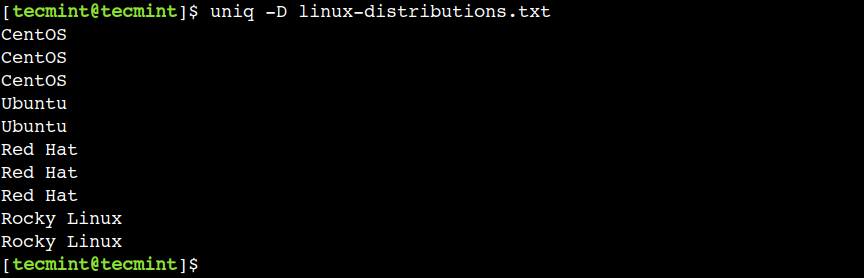
Đầu ra trên không hiển thị các dòng UBUNTU, CENTOS, và Alpine vì chúng là những dòng duy nhất.
6. Hiển thị các dòng trùng lặp theo các nhóm trên dòng mới
Trong ví dụ trước, chúng ta đã in tất cả các dòng trùng lặp. Tuy nhiên, chúng ta có thể làm cho đầu ra tương tự dễ đọc hơn bằng cách tách biệt từng nhóm bằng một dòng mới.
Hãy sử dụng tùy chọn --all-repeated=separate để đạt được điều này:
$ uniq --all-repeated=separate linux-distributions.txt
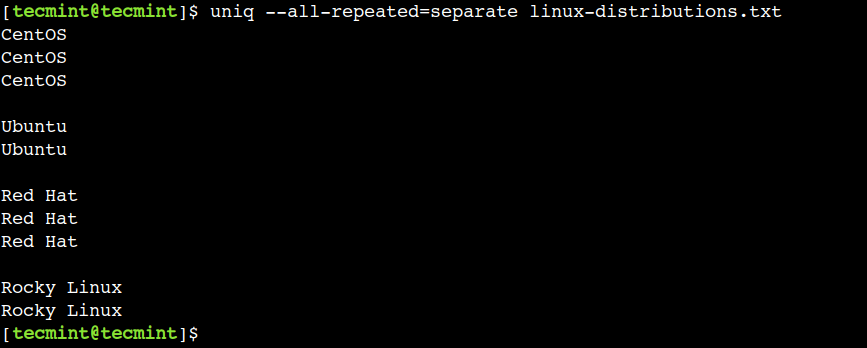
Trong đầu ra trên, chúng ta có thể thấy rằng mỗi nhóm trùng lặp được tách biệt bằng một dòng mới.
7. In chỉ các dòng duy nhất từ một tệp
Trong những ví dụ trước, chúng ta đã thấy cách in các dòng trùng lặp. Tương tự, chúng ta cũng có thể chỉ định lệnh uniq để chỉ in các dòng không trùng lặp.
Bây giờ, hãy sử dụng tùy chọn -u để chỉ in các dòng duy nhất:
$ uniq -u linux-distributions.txt

Ở đây, chúng ta có thể thấy rằng lệnh uniq hiển thị các dòng không bị trùng lặp.
8. Xóa các dòng trùng lặp không liền kề trong tệp
Một trong những hạn chế nhỏ của lệnh uniq là nó chỉ xóa các mục trùng lặp liền kề. Tuy nhiên, đôi khi chúng ta muốn xóa các mục trùng lặp bất kể thứ tự của chúng trong tệp đã cho.
Trong những trường hợp như vậy, trước tiên, chúng ta có thể sắp xếp nội dung tệp và sau đó đưa ra lệnh uniq thông qua dòng lệnh như được hiển thị.
$ sort linux-distributions.txt | uniq
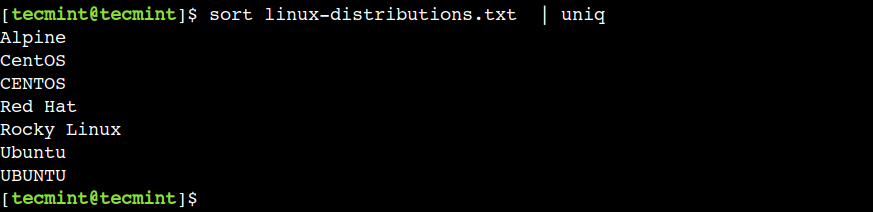
Trong ví dụ này, chúng ta đã sử dụng các lệnh sort và uniq mà không có bất kỳ tùy chọn nào. Tuy nhiên, chúng ta cũng có thể kết hợp các tùy chọn được hỗ trợ khác với các lệnh này.
Trong hướng dẫn này, chúng ta đã tìm hiểu uniq command sử dụng các ví dụ thực tế.