Trong hướng dẫn này, chúng ta sẽ tìm hiểu về lệnh cut cùng với các ví dụ trong dòng lệnh Linux. Sau khi theo dõi hướng dẫn này, người dùng dòng lệnh Linux sẽ có thể sử dụng lệnh cut một cách hiệu quả trong cuộc sống hàng ngày của họ.
Dưới dạng người dùng Linux, chúng ta tương tác với các tệp văn bản một cách thường xuyên. Một trong những thao tác thông thường chúng ta thực hiện trên các tệp này là lọc văn bản. Linux cung cấp nhiều công cụ dòng lệnh cho việc lọc văn bản, chẳng hạn như – grep, fgrep, sed, awk và còn nhiều công cụ khác.
Tuy nhiên, trong hướng dẫn này, chúng ta sẽ thảo luận về một công cụ lọc văn bản khác được gọi là cut, dùng để loại bỏ một phần cụ thể từ dòng đầu vào. Lệnh cut thực hiện việc lọc dựa trên vị trí byte, ký tự, trường và dấu phân cách.
Cú pháp lệnh cut
Cú pháp của lệnh cut tương tự như bất kỳ lệnh Linux nào khác:
$ cut ... [FILE-1] [FILE-2] ...
Trong cú pháp trên, dấu ngoặc nhọn () đại diện cho các đối số bắt buộc trong khi các dấu ngoặc vuông ([]) đại diện cho các tham số tùy chọn.
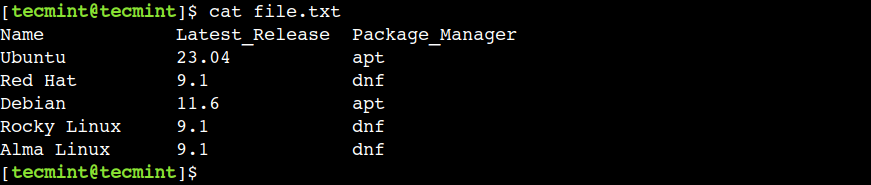
Bây giờ chúng ta đã quen thuộc với cú pháp của lệnh cut. Tiếp theo, hãy tạo một tệp mẫu để sử dụng làm ví dụ:
$ cat file.txt
1. In byte đầu tiên của tệp
Lệnh cut cho phép chúng ta trích xuất văn bản dựa trên vị trí byte sử dụng tùy chọn -b.
Hãy sử dụng lệnh dưới đây để trích xuất byte đầu tiên từ mỗi dòng của tệp:
$ cut -b 1 file.txt
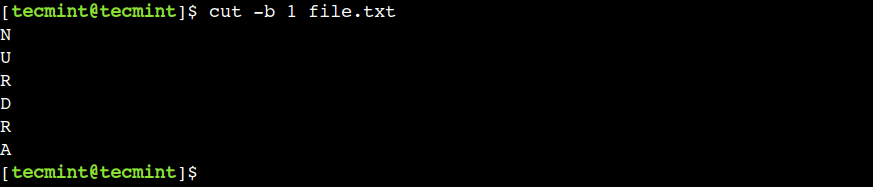
Trong ví dụ này, chúng ta có thể thấy rằng lệnh cut chỉ hiển thị ký tự đầu tiên vì tất cả các ký tự có độ dài một byte.
2. In nhiều byte của tệp
Trong ví dụ trước, chúng ta đã thấy cách chọn một byte đơn từ tệp. Tuy nhiên, lệnh cut cũng cho phép chúng ta chọn nhiều byte bằng cách sử dụng dấu phẩy.
Hãy sử dụng lệnh dưới đây để chọn bốn byte đầu tiên từ tệp:
$ cut -b 1,2,3,4 file.txt
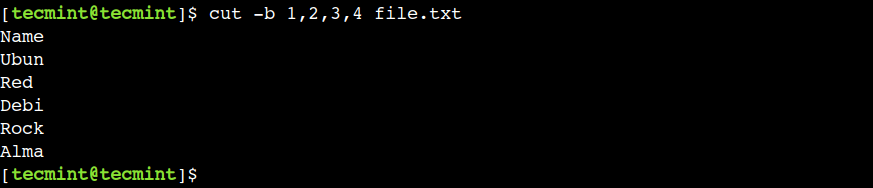
Trong ví dụ này, chúng ta đã chọn các byte liên tiếp nhưng điều này không bắt buộc. Chúng ta có thể sử dụng bất kỳ vị trí byte hợp lệ nào với lệnh cut.
3. In một phạm vi byte của tệp
Trong ví dụ trước, chúng ta đã sử dụng dấu phẩy để chọn các byte liên tiếp. Tuy nhiên, phương pháp này không phù hợp nếu chúng ta muốn chọn một số lượng lớn byte liên tiếp. Trong trường hợp như vậy, chúng ta có thể sử dụng dấu gạch ngang (-) để chỉ định phạm vi byte.
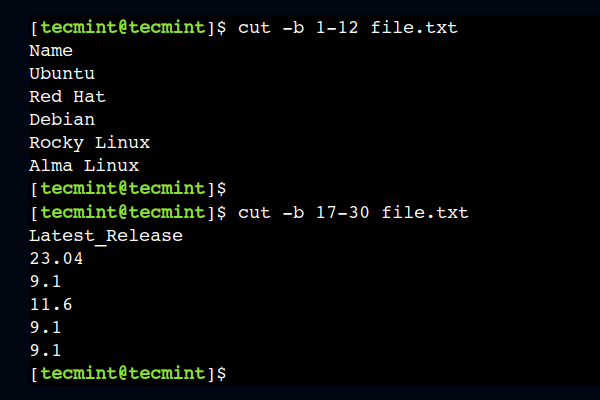
Để hiểu điều này, hãy sử dụng 1-12 như một phạm vi byte để chọn mười hai byte đầu tiên từ mỗi dòng:
$ cut -b 1-12 file.txt
Theo cách tương tự, chúng ta cũng có thể chọn một phạm vi byte từ phần trung tâm. Ví dụ, lệnh dưới đây chọn các byte từ số cột 17 đến 30:
$ cut -b 17-30 file.txt
4. In định vị byte bắt đầu của tệp
Đôi khi chúng ta muốn trích xuất toàn bộ văn bản từ vị trí byte nhất định. Trong trường hợp như vậy, chúng ta có thể bỏ qua vị trí byte kết thúc.
Ví dụ, chúng ta có thể sử dụng lệnh sau để in tất cả byte bắt đầu từ vị trí 17:
$ cut -b 17- file.txt
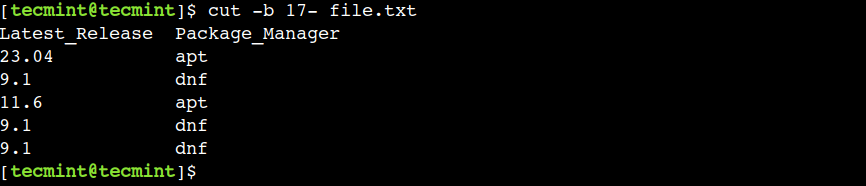
Trong lệnh trên, số 17 đại diện cho vị trí byte bắt đầu trong khi dấu gạch ngang (-) đại diện cho cuối dòng.
5. In định vị byte kết thúc của tệp
Đối với trường hợp tương tự, chúng ta cũng có thể chỉ định vị trí byte kết thúc duy nhất. Ví dụ, lệnh dưới đây in tất cả các byte từ đầu dòng cho đến cột thứ 12:
$ cut -b -12 file.txt
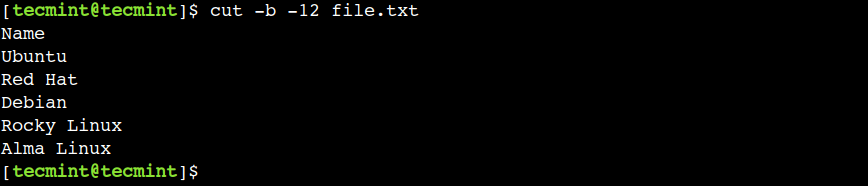
Trong lệnh trên, dấu gạch ngang (-) đại diện cho đầu dòng trong khi số 12 đại diện cho vị trí byte kết thúc.
6. Cắt byte đầu tiên theo vị trí ký tự
Trong những phần cuối cùng, chúng ta đã thấy làm thế nào để thực hiện trích xuất văn bản dựa trên vị trí byte. Bây giờ, hãy xem cách thực hiện trích xuất văn bản theo vị trí ký tự.
Để làm được điều này, chúng ta có thể sử dụng tùy chọn -c để cắt byte đầu tiên từ xâu nhiều byte sau:
$ echo école | cut -b 1
�
Trong đầu ra trên, chúng ta có thể thấy rằng, lệnh cut hiển thị một dấu chấm hỏi thay vì ký tự é. Điều này xảy ra vì chúng ta đang cố gắng in byte đầu tiên từ xâu nhiều byte.
Bây giờ, hãy sử dụng tùy chọn -c để cắt cùng một ký tự nhiều byte và quan sát kết quả:
$ echo école | cut -c 1
é
Trong đầu ra trên, chúng ta có thể thấy rằng bây giờ lệnh cut hiển thị đầu ra được mong đợi.
Đáng lưu ý rằng, không phải tất cả các phiên bản của lệnh cut hỗ trợ ký tự nhiều byte. Ví dụ, Ubuntu và các bản phái của nó không hỗ trợ ký tự nhiều byte.
Để hiểu điều này, hãy chạy cùng lệnh trên Linux Mint được phái sinh từ Ubuntu:

Ở đây chúng ta có thể thấy rằng, lệnh cut xem xét cả ký tự nhiều byte và ký tự một byte như nhau. Vì vậy nó không tạo ra đầu ra mong đợi.
7. Cắt xâu bởi dấu phân cách trong Linux
Mặc định, lệnh cut sử dụng dấu TAB làm dấu phân cách. Tuy nhiên, chúng ta có thể ghi đè lên hành vi mặc định này bằng cách sử dụng tùy chọn -d.
Thường xuyên, tùy chọn -d được sử dụng cùng với tùy chọn -f được sử dụng để chọn một trường cụ thể.
Để hiểu điều này, hãy sử dụng ký tự trống như một dấu phân cách và in hai trường đầu tiên bằng tùy chọn -f:
$ cut -d " " -f 1,2 file.txt

Trong ví dụ trên, chúng ta đã sử dụng dấu phẩy với tùy chọn -f để chọn nhiều trường.
8. In tất cả byte hoặc ký tự trừ những ký tự đã chọn
Đôi khi, chúng ta muốn in tất cả các ký tự trừ một số ký tự. Trong trường hợp như vậy, chúng ta có thể sử dụng tùy chọn --complement. Như tên gọi, tùy chọn này in tất cả các cột ngoại trừ các cột được chỉ định.
$ cut -c 1 --complement file.txt
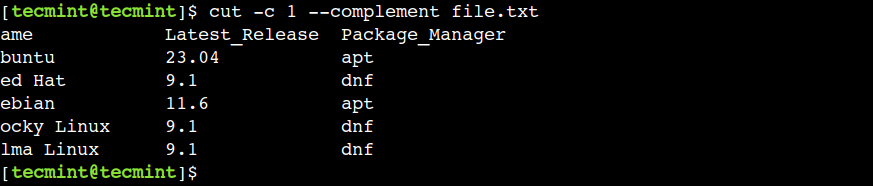
Trong đầu ra trên, chúng ta có thể thấy rằng tùy chọn --complement in tất cả các ký tự trừ ký tự đầu tiên.
Đáng lưu ý rằng, trong ví dụ này, chúng ta đã sử dụng dấu phẩy để chọn nhiều trường. Tuy nhiên, chúng ta cũng có thể sử dụng các dải hỗ trợ khác. Chúng ta có thể tham khảo các ví dụ đầu tiên nhiều hơn trong hướng dẫn này để hiểu thêm về các dải.
Trong hướng dẫn này dành cho người mới, chúng ta đã thảo luận về các ví dụ thực tế của lệnh cut với việc lọc văn bản dựa trên vị trí byte, vị trí ký tự và dấu phân cách.